
The research paper titled Seed-Music: A Unified Framework for High-Quality and Controlled Music Generation introduces a suite of systems designed for music generation and editing, focusing on fine-grained control and high-quality output. This system leverages cutting-edge generative models, including auto-regressive language models and diffusion-based approaches, to handle both vocal and instrumental music generation. The key contribution of this work is its ability to lower the barriers to music creation, making it accessible for both professionals and amateurs.
Problem Statement
Music generation is a complex task due to the intricacies of vocal and instrumental compositions, which require coherence over short and long time frames, and the system must capture nuances like melody, harmony, rhythm, and expressive techniques. Additionally, the generation and editing of vocal music pose unique challenges, such as overlapping sounds, varied pitch ranges, and the need to maintain high-quality output even with limited data or input from users.
Seed-Music Framework Overview
The Seed-Music system is built around a unified framework that integrates various input modalities like lyrics, style descriptions, and audio references. This framework supports two main workflows: controlled music generation and post-production editing.
For controlled music generation, users can provide inputs such as lyrics, voice prompts, and musical scores, and the system generates a corresponding musical piece, ensuring high fidelity and coherence. For post-production, the system offers tools to edit aspects like lyrics and melody directly on existing audio tracks.
The system uses three core components:
- Representation Learning Module: This compresses the audio waveform into intermediate representations, which serve as the basis for further processing.
- Generator: This component processes user inputs and generates intermediate representations for the desired musical output.
- Renderer: This final stage synthesizes high-quality audio based on the intermediate representations, ensuring the generated output sounds natural and coherent.
Core Contributions
- Auto-Regressive and Diffusion Models Integration: The paper introduces a framework that balances the strengths of both auto-regressive models (for sequence generation) and diffusion models (for audio refinement).
- Zero-Shot Singing Voice Conversion: This allows users to input a short speech or singing sample, and the system can synthesize a singing voice with similar timbre and characteristics.
- Interactive Music Editing: Users can alter specific elements like vocals or instruments in an existing track without needing to regenerate the entire audio file.
Applications of Seed-Music
Seed-Music is particularly suited for various music-related workflows, including:
- Vocal and Instrumental Generation: Both vocals and instrumental tracks can be generated, providing users with full compositions based on multi-modal inputs.
- Music Editing: Existing tracks can be refined by modifying the melody, lyrics, or timbre, making it an ideal post-production tool.
- Zero-Shot Voice Conversion: Users can personalize generated music by introducing their voice as a reference, ensuring the output aligns with their vocal style.
Potential Impact on Music Creation
The Seed-Music framework revolutionizes the music creation process by offering an easy-to-use interface for generating and editing music. This lowers the entry barrier for novices while giving professionals the tools to refine and enhance their music production.
The integration of multiple input types (text, audio, style prompts) makes the system versatile, applicable in various creative domains such as game development, film scoring, and personal music production.
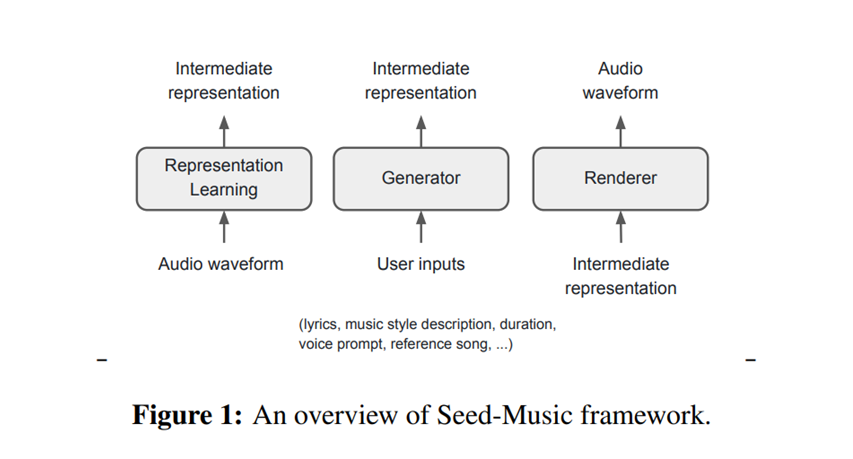
Fig: Overview of the Seed-Music framework, showing the flow of data from user inputs to the final audio output. This figure is critical for understanding how the system works and should be included in the article.
Conclusion
Seed-Music demonstrates a powerful step forward in AI-powered music generation, offering flexibility, ease of use, and high-quality results across diverse music production tasks. Its capacity for controlled generation, zero-shot voice conversion, and fine-grained editing makes it a valuable tool for musicians and creators alike.
If you follow Kanye West, these posters are a great addition. Get them here: https://www.kanyewestposters.com