
A team from UNC Chapel Hill has introduced an innovative framework called MAGICORE (Multi-Agent Iteration for Coarse-to-Fine Refinement), aimed at enhancing reasoning capabilities in Large Language Models (LLMs) like GPT-3.5 and Llama-3-8B. Their solution directly addresses significant challenges faced by LLMs in problem-solving tasks, particularly when models need to improve the quality of their answers through refinement.
This new approach holds the promise of revolutionizing the way LLMs refine and correct their outputs, making them more accurate and resource-efficient. In this article, we will delve into the core aspects of this research, its methodology, results, and implications for the future of artificial intelligence.
The Problem with Existing Refinement Techniques
The concept of refinement in AI models involves improving generated answers through feedback. While existing strategies such as Self-Consistency or Best-of-k sampling help, they reach a point of saturation where further refinement or additional samples cease to enhance accuracy. Current methods also encounter three major issues:
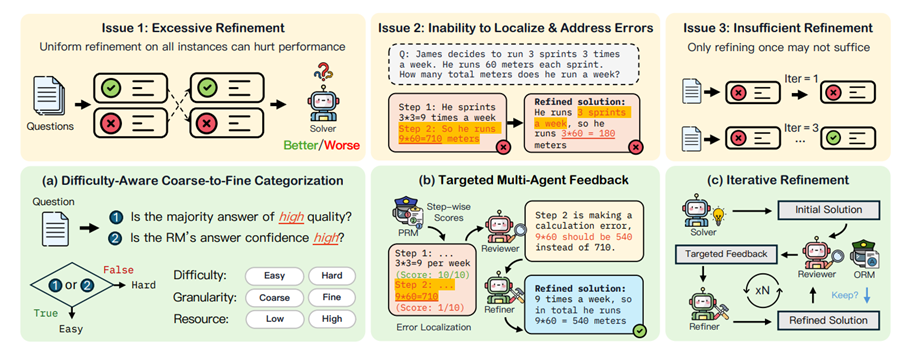
- Excessive Refinement: Over-correcting solutions by refining all instances indiscriminately often leads to worsening of previously correct solutions.
- Error Localization Challenges: LLMs typically struggle to pinpoint specific errors in their reasoning process, which limits their ability to provide targeted corrections.
- Insufficient Refinement: There’s no easy way to determine when enough refinement iterations have been done, leading to either premature stopping or inefficient overuse of resources.
How MAGICORE Works?
MAGICORE proposes a unique solution to these problems by employing a multi-agent system that uses coarse-to-fine refinement, adapting its approach based on the difficulty of the problem at hand. Instead of applying blanket refinement to all cases, MAGICORE distinguishes between easy and hard problems, offering a more efficient process.
Multi-Agent System: MAGICORE incorporates three agents:
- Solver: Generates an initial reasoning chain.
- Reviewer: Provides targeted feedback on the solution based on step-wise reward model (RM) scores.
- Refiner: Improves the solutions using the feedback provided.
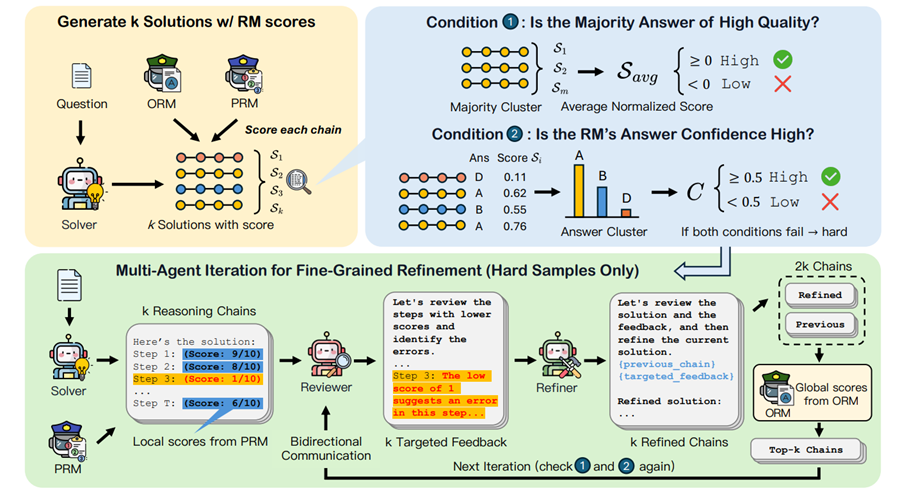
Adaptive Refinement: For easy problems, MAGICORE uses a basic aggregation strategy, while harder problems go through an iterative refinement process, focusing on error localization and correction. The refinement process continues until a satisfactory solution is reached or a maximum number of iterations is completed.
External Reward Models: MAGICORE uses global (ORM) and local (PRM) reward models to assess the correctness of each solution step. This allows for more precise feedback compared to LLMs self-verifying their work.
Iterative Process: This system creates a loop between the Reviewer and the Refiner, ensuring that hard problems receive continuous refinement until the solution improves.
Methodology and Results
The research team tested MAGICORE on five math reasoning datasets—GSM8K, SVAMP, MATH, MMLU, and SAT—using both GPT-3.5 and Llama-3-8B models. The results were groundbreaking:
- Performance Gains: After just one iteration, MAGICORE surpassed existing refinement techniques like Self-Consistency by 3.4% and Best-of-k sampling by 3.2%. These gains increased with further iterations, and unlike other methods, MAGICORE’s performance continued to improve even after multiple refinements.
- Efficiency: MAGICORE achieved higher accuracy while using less than half the number of samples compared to baseline methods, showcasing its efficiency in resource allocation.
- Targeted Refinement: By focusing refinement efforts on hard problems only, MAGICORE avoided over-correction, a common pitfall in previous refinement strategies.
The following table summarizes the key aspects of the MAGICORE framework:
| Problem | Methodology | Results | Conclusion |
|---|---|---|---|
| Over-refinement and error localization issues in LLMs | Multi-agent iterative framework, step-wise reward models for error localization, adaptive coarse-to-fine refinement | Consistent performance gains of 3-4% across multiple datasets and models, better sample efficiency | MAGICORE’s adaptive system significantly outperforms baseline methods by focusing refinement where it is most needed, ensuring better use of computational resources. |
Broader Implications and Future Directions
MAGICORE’s implications for AI go beyond its application to math reasoning tasks. The framework demonstrates that LLMs, which previously struggled with iterative reasoning improvements, can now effectively refine their solutions through targeted feedback.
The method’s ability to adaptively allocate resources also suggests a future where LLMs can become even more efficient at solving complex problems without the need for excessive computation.
Potential future developments could include expanding MAGICORE to handle more diverse types of reasoning beyond math, such as natural language understanding and code generation. The use of multi-agent systems could also inspire similar architectures in other areas of AI, such as collaborative multi-agent reinforcement learning or even autonomous decision-making systems.
Key Takeaways from the Research
- Efficient Refinement: MAGICORE improves performance by selectively refining only hard problems, leading to better accuracy with fewer samples.
- Multi-Agent Collaboration: The system’s use of separate agents for solving, reviewing, and refining creates a more robust problem-solving loop.
- External Reward Models: MAGICORE leverages external feedback, enhancing LLMs’ ability to correct their own mistakes.
- Iterative Process: Unlike traditional methods that plateau, MAGICORE continues to improve as more refinement iterations are applied.
Final Thoughts
MAGICORE represents a significant advancement in the field of AI, particularly in how LLMs handle reasoning tasks. Its novel approach to refinement, based on problem difficulty and multi-agent collaboration, offers a more efficient and accurate way to enhance AI performance. By refining only where necessary, and using targeted feedback from external models, MAGICORE sets a new standard for resource-efficient, iterative learning in large language models.
Check out the Paper. All credit for this research goes to the researchers of this project.
[…] is a tool that simplifies the R&D process. It automates boring, repetitive tasks, making it easier for companies to come up with new ideas, […]