
Artificial intelligence and natural language processing (NLP) have witnessed rapid advancements in recent years, with text embeddings playing a pivotal role in numerous applications such as information retrieval, clustering, classification, and text matching.
One of the latest innovations in this domain is Jina-Embeddings-V3, a state-of-the-art multilingual text embedding model developed by Jina AI.
This model is designed to enhance the efficiency and quality of text embeddings, especially for multilingual data and long-context retrieval tasks. In this article, we will explore the breakthroughs introduced by Jina-Embeddings-V3, its underlying technology, and its practical applications.
Summary Table
| Aspect | Description |
|---|---|
| Problem | Existing models struggle with multilingual data, long-context tasks, and task-specific adaptation. |
| Methodology | Uses XLM-RoBERTa backbone with LoRA adapters, RoPE for long sequences, and Matryoshka Representation Learning for embedding truncation. |
| Result | Outperforms leading models on multilingual and long-context tasks, with superior efficiency and scalability. |
| Use Case | Suitable for search engines, customer support, content filtering, sentiment analysis, and more. |
The Problem: Limitations of Existing Embedding Models
Text embedding models are the backbone of many modern NLP tasks. They transform text data into high-dimensional vectors, allowing machines to understand and process semantic relationships between texts. However, despite their widespread use, many existing embedding models face several key limitations:
- Language Barriers: Many models struggle with multilingual tasks, offering suboptimal performance when handling non-English text.
- Long-Context Handling: Most models have limited support for processing long documents, usually truncating or losing context beyond a certain token length.
- Task-Specific Adaptations: While some models claim to be general-purpose, they often require additional fine-tuning to perform well on specific tasks such as document retrieval or classification.
- Scalability: With model sizes reaching billions of parameters, deploying such models in real-world applications becomes resource-intensive and costly.
The Solution: Jina-Embeddings-V3
Jina AI introduced Jina-Embeddings-V3 to address these challenges. This model stands out due to its ability to handle multilingual tasks and long-context retrieval with remarkable efficiency. Let’s break down its core innovations:
1. Multilingual Embedding Capabilities
Jina-Embeddings-V3 is designed to perform exceptionally well across multiple languages, supporting tasks in over 89 languages. Its performance on multilingual tasks has been demonstrated to outperform several leading proprietary models, including OpenAI and Cohere.
2. Handling Long-Context Retrieval
Traditional models struggle with long documents, often losing crucial information due to token length limitations. Jina-Embeddings-V3 supports text sequences of up to 8192 tokens using Rotary Position Embeddings (RoPE), a technique that preserves relative positional dependencies within the text. This innovation makes it highly suitable for tasks involving lengthy documents, such as research papers or legal documents.
3. Task-Specific Low-Rank Adaptation (LoRA) Adapters
Unlike previous models that required manual fine-tuning for specific tasks, Jina-Embeddings-V3 uses LoRA adapters. These lightweight adapters dynamically adjust to the needs of different tasks, such as classification, clustering, and text matching. By freezing the original model weights and introducing LoRA layers, Jina-Embeddings-V3 optimizes for specific tasks while keeping memory and computation requirements low.
4. Matryoshka Representation Learning (MRL)
A unique feature of Jina-Embeddings-V3 is Matryoshka Representation Learning, which allows for flexible truncation of embedding dimensions without compromising performance. Users can reduce the embedding size for efficiency, making the model more adaptable for resource-constrained environments, such as mobile or edge computing.
Methodology: How Jina-Embeddings-V3 Works
Jina-Embeddings-V3 uses a transformer-based architecture, specifically an adaptation of XLM-RoBERTa, to generate embeddings. Here’s a simplified overview of its architecture:
- Transformer Backbone: The model’s core is built on the XLM-RoBERTa transformer, which has been modified to handle longer sequences and task-specific encoding.
- RoPE for Long Sequences: Instead of traditional positional embeddings, the model uses RoPE to ensure that text sequences of up to 8192 tokens can be processed efficiently without losing important contextual information.
- LoRA Adapters: These adapters allow the model to fine-tune its embeddings for different tasks dynamically. For example, when performing text classification, the model activates the classification adapter, while in a retrieval task, it uses retrieval adapters.
The training process is divided into three stages:
- Pre-Training: The model is trained on large multilingual datasets with sequences of varying lengths. The training begins with shorter sequences and gradually shifts to longer ones.
- Fine-Tuning: During this phase, the model learns to generate single-vector embeddings for text sequences. This step ensures that the embeddings capture the semantic essence of the text.
- Task-Specific Adapter Training: The final stage involves training the LoRA adapters for specific tasks like classification, retrieval, or clustering, optimizing the model for each use case.
Results: Superior Performance Across Tasks
The results from evaluating Jina-Embeddings-V3 on the MTEB benchmark (a comprehensive benchmark for multilingual text embeddings) are impressive. The model consistently outperformed leading competitors, achieving superior results on both monolingual (English) and multilingual tasks.
- English Tasks: Jina-Embeddings-V3 achieved the highest classification accuracy (82.58%) and the top sentence similarity score (85.8%), demonstrating its robustness for a wide range of tasks.
- Multilingual Tasks: The model performed exceptionally well on multilingual tasks, outperforming competitors like multilingual-e5-large-instruct and Cohere-embed-multilingual-v3.0 in most evaluations.
These results confirm that Jina-Embeddings-V3 is a cost-effective and scalable solution for text embedding tasks, particularly when compared to larger models such as e5-mistral-7b-instruct, which require significantly more computational resources.
Use Cases: Practical Applications of Jina-Embeddings-V3
Jina-Embeddings-V3 can be applied to various NLP tasks across different industries. Here are a few examples:
- Search Engines and Information Retrieval: Its long-context retrieval capability makes it ideal for applications like legal document searches or academic research retrieval systems.
- Multilingual Customer Support: Companies can use Jina-Embeddings-V3 to provide accurate and multilingual customer support by matching queries and responses across languages.
- Content Moderation and Filtering: The model can help platforms filter inappropriate content in multiple languages, ensuring safe and relevant content for users.
- Sentiment Analysis and Classification: Jina-Embeddings-V3’s task-specific adapters can be used for sentiment analysis, categorizing reviews, and classifying content efficiently across languages.
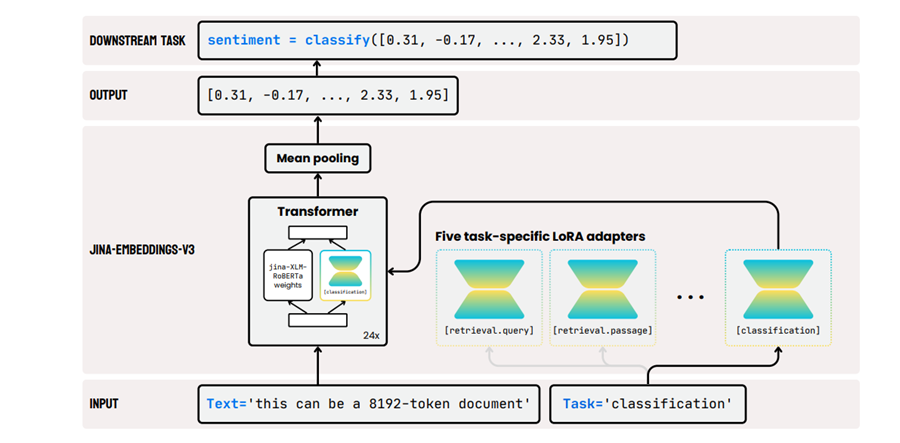
This figure provides a visual representation of the model’s architecture, including the integration of RoPE for long-text processing and the LoRA adapters that enable task-specific tuning.
Conclusion
Jina-Embeddings-V3 represents a significant leap forward in the field of text embeddings, particularly for multilingual data and long-context tasks. By addressing the limitations of previous models and offering a more scalable, adaptable solution, Jina AI’s latest innovation paves the way for more accessible and efficient NLP applications.
FAQs
1. How does Jina-Embeddings-V3 compare to OpenAI's models?
Jina-Embeddings-V3 excels in multilingual support and long-context handling, using Rotary Position Embeddings for sequences up to 8192 tokens. It’s more efficient and scalable for these tasks compared to OpenAI’s models, which can be resource-intensive and may not specialize as deeply in multilingual embeddings or long-context retrieval.
2. What are LoRA adapters, and why are they important for NLP?
LoRA adapters are lightweight, trainable layers that adjust pre-trained models for specific tasks without extensive retraining. They are important because they enable efficient task-specific fine-tuning, reducing computational and memory costs while providing flexibility for various NLP applications.
3. How can I implement long-context retrieval with Jina-Embeddings-V3?
To implement long-context retrieval, prepare your text data to fit within the 8192-token limit of Jina-Embeddings-V3. Use the model’s Rotary Position Embeddings for context preservation and configure it to handle long sequences. Index your documents and query using the model to retrieve relevant information.