
Table of Contents
ToggleResearchers are always looking to improve how models process and compare human language. One important technology is sentence embeddings. These convert sentences into vectors to compare their meanings. This is key for tasks like semantic search and text classification. However, dealing with large datasets can be slow and challenging.
Problems with Traditional Models
Traditional models like BERT and RoBERTa are good at sentence comparisons but are slow with big datasets. For example, comparing sentences in a collection of 10,000 can take up to 65 hours with BERT. This slow speed limits their use in real-time applications like web searches or customer support.
Seeking Faster Solutions
Previous methods to speed things up often hurt performance. Some techniques reduce computational costs but can lower the quality of sentence embeddings. Approaches like averaging BERT outputs or using the [CLS] token have not always been effective compared to older models like GloVe embeddings.
What is Sentence-BERT (SBERT)?
Researchers from the Ubiquitous Knowledge Processing Lab (UKP-TUDA) at Technische Universität Darmstadt have introduced Sentence-BERT (SBERT). This model modifies BERT to handle sentence embeddings more efficiently. SBERT uses a Siamese network architecture, which makes comparing sentence embeddings faster. It cuts the processing time from 65 hours to just five seconds for 10,000 sentences while keeping accuracy high.
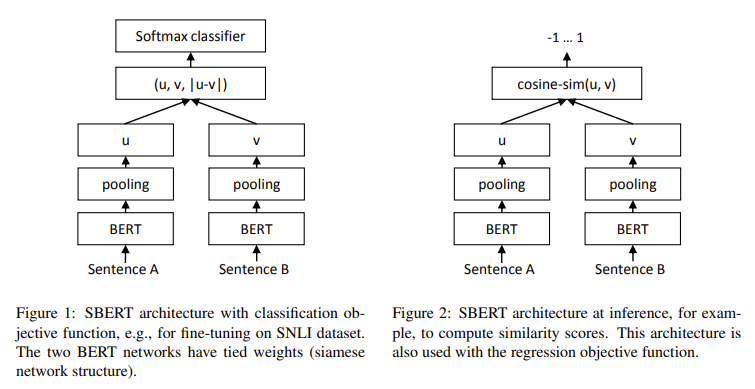
How SBERT Works
SBERT uses different pooling strategies to create fixed-size vectors from sentences. These include MEAN pooling, max-over-time pooling, and the [CLS] token. The model was fine-tuned with large datasets like SNLI and MultiNLI. This fine-tuning helped SBERT perform better than older methods like InferSent and Universal Sentence Encoder.
SBERT achieved high scores on the STS benchmark with a Spearman rank correlation of 79.23 for its base version and 85.64 for the large version. It also performed well in sentiment prediction tasks, with accuracies of 84.88% for movie reviews and 90.07% for product reviews.
Practical Uses
SBERT’s speed and accuracy make it great for large-scale text analysis. It can find similar questions in datasets like Quora in milliseconds, compared to over 50 hours with BERT. The model processes up to 2,042 sentences per second on GPUs, making it faster than other models like the Universal Sentence Encoder and InferSent.
Conclusion
SBERT is a major improvement in sentence embedding technology. It solves the problem of scalability in natural language processing by making sentence comparisons much faster while maintaining high accuracy. Its strong performance across different tasks makes it a valuable tool for anyone working with large amounts of text data.
[…] Traditional models struggle with long documents, often losing crucial information due to token length limitations. Jina-Embeddings-V3 supports text sequences of up to 8192 tokens using Rotary Position Embeddings (RoPE), a technique that preserves relative positional dependencies within the text. This innovation makes it highly suitable for tasks involving lengthy documents, such as research papers or legal documents. […]
[…] Life. After being trained on a dataset of 10,000 stochastically generated initial conditions, the model was able to predict future game states with near-perfect accuracy. The team ran extensive tests, including zero-shot […]
[…] appreciation for Burning Man goes beyond just enjoying the art and atmosphere. He now views it as a model for what the future could look like, particularly in a world where AGI artificial intelligence that matches or exceeds […]