
Large Language Models (LLMs) have traditionally struggled with understanding visual data because they were designed primarily for text processing. To address this, Visual Language Models (VLMs) were developed to merge visual and textual information.
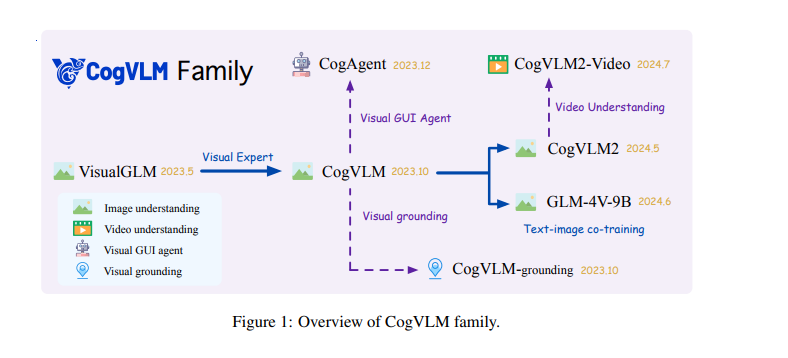
Early models, such as VisualGLM, began integrating these modalities but used basic methods that limited their effectiveness. This pointed to the need for more sophisticated approaches.
Table of Contents
ToggleAdvancements in Visual Language Models
Recent progress has led to the development of more advanced VLMs, like CogVLM. These models aim to combine vision and language features more deeply, improving natural language processing.
Innovations in datasets, such as the Synthetic OCR Dataset, have enhanced these models' abilities in areas like document analysis, graphical user interface (GUI) understanding, and video interpretation.
Introducing the CogVLM2 Family
The latest research from Zhipu AI and Tsinghua University presents the CogVLM2 series, which includes:
- CogVLM2: A versatile model for enhanced image and video understanding.
- CogVLM2-Video: Focused on advanced video analysis.
- GLM-4V: A model exploring broader modalities.
Key improvements in these models include:
- Higher-Resolution Architecture: For detailed image recognition.
- Broader Modalities: Such as visual grounding and GUI agents.
- Innovative Techniques: Like post-downsample for better image processing.
These models are open-source, fostering further research and development in the field.
Training and Methodology
CogVLM2-Video's training involves two key stages:
- Instruction Tuning: Uses detailed caption and question-answering datasets with a learning rate of 4e-6.
- Temporal Grounding Tuning: Focuses on time-based understanding using the TQA Dataset, with a learning rate of 1e-6.
The model processes video input in 24 sequential frames and includes a convolution layer in the Vision Transformer for efficient video feature compression.

Evaluation and Performance
CogVLM2 models excel in:
- Video Question-Answering: Achieving top results in benchmarks like MVBench and VideoChatGPT-Bench.
- Image-Related Tasks: Outperforming existing models in OCR comprehension, chart and diagram understanding, and general question-answering.
- Versatility: Performing well in video generation and summarization tasks.
Conclusion
The CogVLM2 series represents a major leap in integrating visual and language processing. By overcoming the limitations of earlier models, these new models offer advanced capabilities in interpreting and generating content from images and videos.
The CogVLM2 family sets a new standard for open-source visual language models, with significant advancements in both image and video understanding and opportunities for future research.
[…] breakthrough could change how AI tasks, such as training language models, are performed. Instead of needing huge data centers, these tasks could be done on smaller devices, […]
[…] As deepfake technology becomes increasingly sophisticated, the potential for misuse has grown. Google’s new feature will utilize its advanced AI capabilities to detect and label AI-generated images, ensuring users are aware of the nature of the content they encounter. This move is part of Google’s broader strategy to maintain the integrity of information on the internet and protect users from being misled by manipulated visuals. […]