
In recent times the deep learning models keep getting bigger and more complex. But making them larger isn't always the best way to improve performance. A new approach called the Mixture-of-Experts (MoE) model, offers a smart solution to scaling models without using too many resources. The research paper "GRIN: GRadient-INformed Mixture of Experts" introduces an innovative way to train these models more effectively.
Mixture-of-experts models, or MoE for short, work by activating only a small group of specialized "experts" for each task. This makes them efficient because not all parts of the model are used at once. However, training these models has been challenging because the way they choose which experts to activate isn’t easy to optimize. GRIN provides a new method to solve this problem, making MoE models faster and more accurate.
Key Insights from the Research
| Problem | Solution | Findings | Conclusion |
|---|---|---|---|
| Hard-to-train expert networks | SparseMixer-v2 improves gradient estimation | Better performance across tasks like MMLU, HellaSwag, and more | GRIN improves MoE training and boosts model efficiency. |
| Inefficient model scaling | Tensor and pipeline parallelism | Efficient scaling without token dropping or extra computation | GRIN scales large models efficiently while using fewer resources. |
The Challenge: Hard-to-Train Expert Networks
MoE models have a great ability to scale. Instead of using all the experts in the model at the same time, MoE only activates a few experts that are most suitable for a given task. However, the challenge comes from how MoE decides which experts to use. The decision-making process, called expert routing, produces results that are hard to adjust using traditional training methods like backpropagation, which is the key method for training most deep learning models.
Because of this, training MoE models has been less effective compared to dense models, where all parts of the model are always activated. Even though MoE models have the potential to be faster and more efficient, this routing challenge has slowed down their adoption.
How GRIN Improves Training
To fix this issue, the researchers developed GRIN, a new method that allows better training of MoE models by improving the way expert routing is handled. The key innovation of GRIN is a technique called SparseMixer-v2. This technique creates better gradient estimates, which are crucial for adjusting the model during training.
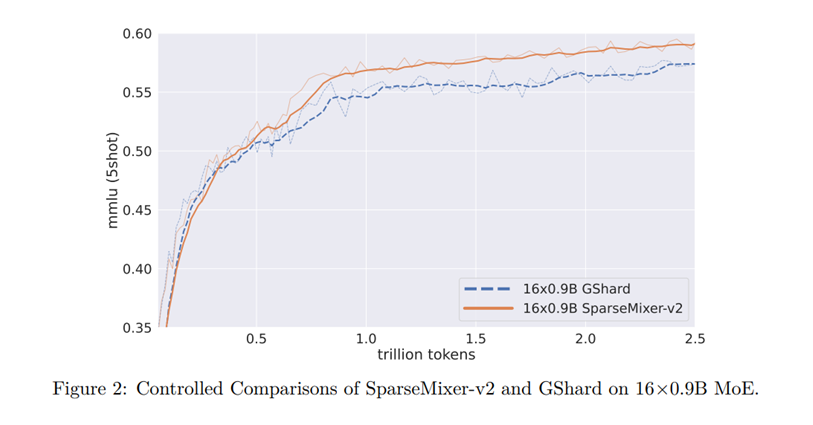
With SparseMixer-v2, GRIN can replace the complex routing decisions with a simpler system during training, allowing the model to learn efficiently. This new system estimates the gradient, which helps the model improve and become more accurate over time.
How GRIN Works: More Efficient and Scalable Models
The GRIN method is all about making models smarter and more efficient. One of the biggest advantages of GRIN is that it doesn’t need to "drop" any tokens (small pieces of input data) during training, which is common in other MoE models. Instead, GRIN uses tensor parallelism and pipeline parallelism, making the training process faster and smoother without cutting any corners.
This means that GRIN can build and train larger models without overloading the system. For example, GRIN’s MoE model, with a total of 42 billion parameters, only needs to activate 6.6 billion parameters at a time. Even with fewer active parameters, it performs just as well, or better, than larger models that are fully active. This makes GRIN a game-changer for creating big models without needing excessive computational power.
The Results: A New Standard for Performance
GRIN’s approach has proven to be highly effective. In multiple tests, it outperformed models with more parameters while using fewer resources. Here are some highlights of GRIN’s performance across several benchmarks:
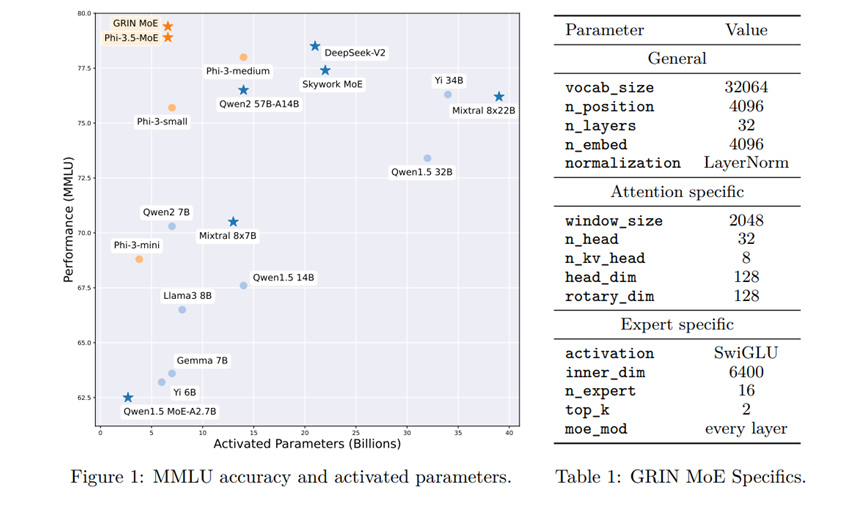
- MMLU (Massive Multitask Language Understanding): GRIN scored 79.4, beating many larger models.
- HellaSwag: A common-sense reasoning test where GRIN achieved a score of 83.7.
- HumanEval: For tasks involving code generation, GRIN scored 74.4, showcasing its flexibility.
- MATH: GRIN excelled in math problem-solving with a score of 58.9.
Despite using fewer parameters during inference, GRIN managed to outperform dense models with more active parameters, proving that efficiency doesn't have to come at the cost of performance.
Why GRIN is Important for Deep Learning
The GRIN model is a major step forward for deep learning. It solves a problem that has long limited the potential of MoE models: how to train them effectively. By improving the way the model learns which experts to activate, GRIN makes it possible to build large, efficient models that can handle a wide range of tasks with fewer resources.
In simple terms, GRIN shows that bigger models aren't always better if you can use smarter ways to train them. With GRIN, we can create models that work just as well as, or even better than, much larger models while using less computational power. This is especially important for real-world applications where the cost and time needed to train models can be very high.
Final Thoughts: The Future of Efficient AI Models
GRIN's innovative approach to training MoE models is a game-changer. By solving the key issue of expert routing and introducing new ways to estimate gradients, GRIN makes deep learning models more efficient and scalable. This means we can expect future models to do more with less, making AI more accessible and reducing the environmental impact of large-scale computing.
As deep learning continues to evolve, GRIN paves the way for building powerful AI models that are both smart and efficient. This could revolutionize industries like healthcare, finance, and technology by providing faster, more accurate models without the need for supercomputers.
Read More Research Paper Analysis!