
Deep neural networks have revolutionized fields like computer vision and natural language processing. However, despite their success, these models often fail to generalize in ways that humans do. A recent study by researchers from Google DeepMind, Technische Universität Berlin, and other institutions reveals a key misalignment between how machines and humans perceive the world.
By aligning machine learning models with human-like conceptual understanding, the researchers aim to create more robust, interpretable, and human-like AI systems.
The Problem with Current Neural Networks
Human vs. Machine Learning
Humans categorize and understand visual information in a hierarchical manner, ranging from fine-grained to coarse distinctions. For example, we can easily distinguish between a dog and a fish on a broad level (both are animals) and between a golden retriever and a poodle on a finer level.
However, neural networks do not naturally encode this multi-level abstraction. They often capture local features like texture or color but struggle to represent more abstract relationships, such as the conceptual difference between animals and vehicles.
The Impact of Misalignment
This misalignment leads to two main problems. First, neural networks lack robustness when faced with new or unseen data, known as distribution shift. Second, these models often exhibit overconfidence in their predictions, even when incorrect, which is unlike human behavior where uncertainty typically correlates with accuracy. This discrepancy raises concerns about the reliability and interpretability of AI in real-world applications.
AligNet – A New Framework for Human-like AI
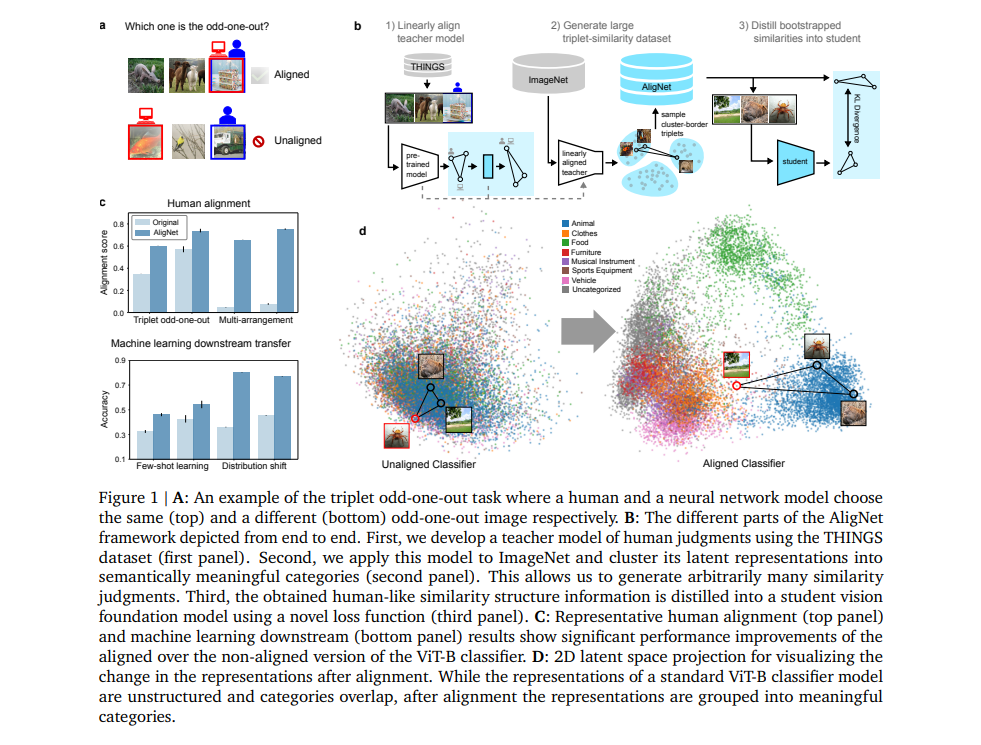
To address this issue, the researchers developed the AligNet framework, which involves aligning neural network representations with human judgment. They started by training a "teacher model" to imitate human judgments, using data from a behavioral dataset called THINGS.
This dataset includes human responses to visual similarity tasks, like identifying the odd-one-out from a set of three images. The model was then used to distill human-like conceptual structures into state-of-the-art vision models.
Transferring Knowledge to Vision Models
The AligNet framework consists of a three-step process:
- Teacher Model Alignment: The teacher model was aligned with human semantic judgments, especially focusing on triplet odd-one-out tasks where humans select which image is least like the others.
- Generating Human-like Data: The aligned model was used to generate a large dataset of similarity judgments, simulating human-like responses.
- Training Student Models: This generated data was then used to train or fine-tune existing vision models, transferring the human-like alignment to these "student" models.
This approach ensures that the resulting models can better approximate human behavior across a range of tasks and are more robust to variations in the visual data.
Experimenting with Human Alignment
The Levels Dataset
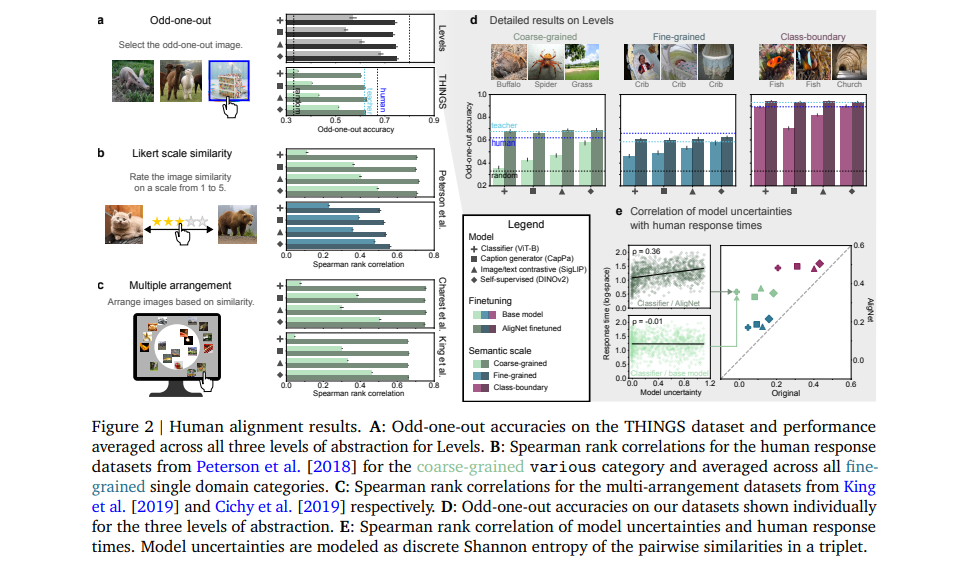
To evaluate the effectiveness of AligNet, the researchers created a new dataset called Levels. This dataset includes human judgments across multiple levels of semantic abstractions: global coarse-grained distinctions (e.g., between animals and vehicles), local fine-grained distinctions (e.g., between different breeds of dogs), and class-boundary distinctions (e.g., identifying an object that doesn’t belong in a set).
Tasks and Performance
In various tasks, including the triplet odd-one-out and multi-arrangement tasks, the AligNet-enhanced models more closely matched human judgments. For example, when asked to identify which of three images was the odd-one-out, the aligned models agreed with human choices up to 62.54% of the time, a significant improvement over traditional models.
Improved Uncertainty Calibration
Additionally, the aligned models showed better-calibrated uncertainty, aligning more with human-like uncertainty. In other words, these models were less likely to be overconfident in their incorrect predictions, reflecting a more human-like understanding of visual concepts.
Improving Model Generalization and Robustness
Improved Performance on Downstream Tasks
Aligning models with human-like structures not only improves their ability to mimic human judgment but also enhances their performance on various machine learning tasks. The study tested the aligned models on a range of downstream tasks, including few-shot learning (classifying images with very few examples) and distribution shift challenges, where the models encounter data different from their training set.
Distribution Shift and One-Shot Learning
Aligned models exhibited better generalization capabilities in few-shot learning, outperforming their unaligned counterparts. They also demonstrated increased robustness when dealing with distribution shifts, showing a notable improvement in accuracy across different test scenarios.
For instance, on the BREEDS benchmark datasets, which test models on new variations of data categories, AligNet models performed consistently better than unaligned models.
Enhancing Robustness Against Adversarial Examples
The study also explored the models' robustness using the ImageNet-A dataset, known for its adversarial nature. Traditional models often misclassify these challenging images, but the AligNet models showed up to a 9.5 percentage point improvement in accuracy, indicating a significant enhancement in handling difficult, real-world data.
Broader Implications for AI Development
Towards More Human-like AI
The AligNet framework represents a step toward creating AI systems that align more closely with human cognition. By incorporating hierarchical human-like knowledge into neural networks, this approach paves the way for developing more interpretable, reliable, and human-like AI.
This has potential applications beyond computer vision, extending to areas like natural language processing, where understanding the global structure of information is crucial for improved performance and interaction.
Future Directions and Applications
Future research could involve applying the AligNet methodology to other domains, such as language models, to enhance their understanding of context and relationships. Another potential area of exploration is adapting this framework to capture variations in human judgment across different cultures and individuals, making AI systems more inclusive and representative of diverse human perspectives.
Conclusion
The research presented in "Aligning Machine and Human Visual Representations across Abstraction Levels" highlights the importance of aligning AI with human conceptual structures. By bridging the gap between human and machine perception, the AligNet framework offers a promising path toward building more robust and interpretable AI systems.
This work contributes to the ongoing dialogue about how to create AI that not only performs well but also aligns with human values and understanding.
Users also ask these questions
How Does Human-Like Alignment Affect AI's Decision-Making Process?
Human-like alignment significantly influences AI decision-making by improving the model's ability to capture and represent hierarchical relationships similar to those used by humans. Traditional AI models often rely on local features like texture or color for decision-making, which can lead to incorrect or overly confident predictions, especially in scenarios involving unfamiliar or ambiguous data.
By incorporating human-like alignment, such as through the AligNet framework, AI models learn to encode global, multi-level abstractions. This means they can better differentiate between broad categories (e.g., animals vs. vehicles) and more nuanced distinctions within those categories (e.g., different dog breeds). As a result, these aligned models exhibit enhanced generalization, making them more robust in new or shifting environments.
Additionally, human-like alignment calibrates the model's uncertainty more effectively, reducing overconfidence in incorrect predictions and making the AI's decisions more interpretable and trustworthy.
Can AligNet Be Applied to Other Types of Neural Networks Beyond Vision Models?
Yes, the AligNet framework has the potential to be applied to other types of neural networks beyond vision models. Although the current research focuses on aligning vision models with human-like conceptual structures, the underlying principles can be extended to other domains like natural language processing (NLP).
For instance, in NLP, models could be aligned with human-like understanding of semantic relationships and syntax, improving their ability to comprehend and generate language in a more human-like manner. By aligning language models with hierarchical structures that reflect human language processing, we could achieve better contextual understanding and more coherent language generation.
The framework could also be adapted for other domains where hierarchical and multi-level abstraction is crucial, such as audio processing or reinforcement learning, to enhance model performance and robustness.
What Are the Challenges in Scaling the AligNet Framework for Broader Applications?
Scaling the AligNet framework for broader applications involves several challenges. One primary challenge is the availability and collection of large-scale, high-quality human behavioral data. Since the alignment process relies on human judgments to guide model learning, generating or sourcing sufficient data across different domains and abstraction levels can be resource-intensive and time-consuming.
Another challenge is the complexity of aligning models in domains where human judgments are more subjective or context-dependent, such as in language or cultural contexts. This requires careful consideration of individual and cultural variations in human cognition. Furthermore, computational resources pose a challenge, as aligning large-scale models, especially with high-dimensional data, demands significant processing power and optimization strategies to manage the increased complexity.
Lastly, there's the issue of maintaining a balance between capturing human-like representations and preserving the model's original functional capabilities, ensuring that alignment enhances rather than hampers performance.
[…] In response to the shortcomings of OCR-1.0, a groundbreaking advancement has emerged in the form of the General OCR Theory (GOT) model, introduced by researchers from StepFun, Megvii Technology, the University of Chinese Academy of Sciences, and Tsinghua University. As a pivotal component of OCR-2.0, GOT represents a significant leap forward in text recognition technology. […]